 官方微信
官方微信

 官方QQ
官方QQ



一、ABI情报分析方法
该方法是情报分析论文发表方法中的一种,通过从地理叙事的方向为切入点,在空间以及时间上实现活动连接。使得无序或杂乱的情报活动,变得有规律、有序可循,以此为目标活动分析提供新的方向,并且ABI情报分析方法也是多源情报的聚集和关联。在时空数据的基础上,通过对目标活动的发展规律进行分析,从而预测目标活动。与传统的目标分析方法相比较来说,该目标方法通过构建目标的行为谱,为目标的所有特征和规律研究提供了数据上的支持。
而情报分析从本质方面来说,就是利用一系列处理规则,获取对方的计划或者意图。不过, 在实际数据集生成当中比较稀疏,只能够代表小部分的数据。而ABI方法易于对未知事物的发现,并且可以通过活动或实际的层段来对相关的实体进行搜索,也能够识别可能不为网络所知的成员,ABI方法的分析框架如图1所示。
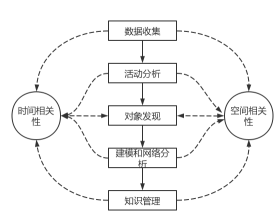
时间和空间为ABI情报分析方法提供了时间相关性和空间相关性两个数据过滤器,从上述框架中就能够看出时空关系贯穿了整个数据情报的分析过程,从数据收集一直到知识管理等各个环节均和时空关系不断迭代。
二、情报分析对目标的识别
在情报分析领域当中可以将实体目标识别划分为多个步骤,具体情报分析流程如图2所示。
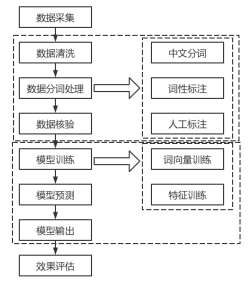
(1)数据采集。该方面主要来源于相关情 报报文,如时间或者情报的内容等。
(2)数据管理。该部分是情报挖掘分析的基础,通过对目标的活动规律、活动轨迹、目标特征以及平台信息等方面的数据为基础进行挖掘, 并对其结果进行保存。数据管理也是对各种不同类型数据的提取、查询以及存储和整理调用。
(3)数据预处理。预处理是对模型进行训练之前的重要部分,该部分主要包含了数据的清洗、数据分词处理以及数据核验等。数据清洗进一步解决了数据中存在的质量问题,而数据分词处理的质量直接对模型质量有着相应的影响。
(4)任务数据挖掘。基于大数据的数据挖 掘和传统数据挖掘两者进行相比较发现,从其概念内涵以及实现目标等方面上来看,两者之间没有存在本质上的差别。二者均是为了获取数据当中所蕴藏的规律性知识,以此实现提前对事物的变化发展趋势进行预知。不过,二者之间不相同的地方则是在对数据挖掘的环境方面出现了变化,其数据量和数据类型方面有了一定程度的提升。但通过对任务的分解,二者均可以满足用户在负载下的要求。由此可见,传统数据挖掘方法同样能够适用于大数据。
例如,以对目标运动发展趋势为例,给出大数据下情报信息分析挖掘的一种合理模型。具体的建模步骤如下:首先,需要对任务数据进行合理的分析,并对完整任务数据进行预处理;其次,在考虑到分解之后的单体数据集的体量依然具备一定规模,这时可以利用RBF神经网络模型或者ABI分析方法,将单体数据集中在每一个数据点上(这里选用了RBF神经网络模型),因此可以将单体数据集中在神经网络模型中,并且和神经元组成庞大的训练集体,最后形成映射; 接着利用SVM(支持向量机)辅助方法,对神经网络模型的优化实现求解,同时还需要针对神经网络中的隐形层进行改善,使得其能够在大数据的帮助下促使数据处理的稳定性得到提高。
(5)数据挖掘算法实现。①特征分类。想要进一步实现数据挖掘算法,可以结合特定的领域进行模型建设分类。接着,利用数据挖掘工具和相关算法对数据源中存在的数据进行扫描分析与分类。其目的主要是利用分类模型,让数据库当中的数据项直接映射到某一个特定的类别当中。通过训练和运行这些独立的模块,完成模型训练。②关联论文发表分析。该方面主要是连接特定的领域,在知识库中建立相对应的关联机制, 并对数据园中的数据实施关联分析。③聚合分析。结合研究所需,搭配知识、聚合相应的信息源,以此可以实现高效检索、导航以及关联等部分功能。同时,可以对数据的聚合进行展示, 从而为更深层次的数据挖掘分析提供有力的支撑。④趋势演变。该部分结合对特定领域的分析,利用预测模型建设的形式,在数据挖掘工具的作用下针对存在时空跨度的数据进行分析, 并且对其趋势演变实施预测,以此辅助用户的研究分析。
三、分布式并行运算的大数据挖掘分析
在针对情报论文发表分析时,还需要注重单台设备性能不足的问题。而Spark分布式并行运算框架的出现,能够有效解决单台设备在进行大数据的海量计算工作时性能不足的问题。Spark框架是当前最为流行的一种大数据处理框架,常常用于离线的大数据处理。可以通过对大数据处理部分的改进,将计算的结果和所使用的数据存储到相应的内存当中。这样既可以降低对磁盘反复读写的消耗,还可以提高设备的运算性能,比较适合应用于迭代任务运算当中,以此促使数据挖掘算法的效率得到提升。该框架的整体可以划分为以下4层。
(1)工具层。该层次,Spark为数据挖掘提供了多种工具,如应用于查询的SparkSQL和应用于流式计算的SparkStreaming以及最后应用于机器学习的MILib和图处理的GraphX。
(2)计算层。将用户的应用程序,分解成了内部执行任务,同时还为其提供了执行容器。
(3)存储层。该层可以实现对分布式文件系统的读取,还可以通过Hadoop集群中所存储的组件数据访问本地数据。
(4)资源调度层。在资源调度层,可以将集群管理器看作YARN,并且可以在自带的集群管理器下实现独立运行。

由此可见,在数据挖掘方面,基于分布式并行运算的挖掘分析方法对目标活动的规律分析具有一定程度的借鉴作用。并且,相对应的算法同样能够适用于对目标活动规律的大数据挖掘。而针对目标活动规律的挖掘分析是情报分析中的重点内容,因此,经过长期积累的论文发表数据表明,对目标活动轨迹的分析,在相应的活动时,均会存在固定频繁的活动区域或者轨迹,而这正是对目标进行身份识别或者多目标意图识别的重要依据之一。所以在目标活动的过程当中针对目标活动轨迹的提取,虽然会存在大量的目标痕迹,但是痕迹越多则是越能够充分、真实地反映出目标的活动轨迹。但目标活动轨迹数据量过多时,会对数据挖掘和情报分析以及数据存储方面造成巨大的压力。这时,就需要对其误差范围进行缩小,还要利用少量的数据表征目标运动轨迹。最后,将结果利用显示功能进行显示。例如以电子地图为背景,将大数据挖掘的结果和目标的活动轨迹在地图上进行显示。在日益增长的数据量下,大数据的挖掘技术发挥其优势,已经成了当前情报分析发展的一大趋势。
相关热词搜索:计算机论文发表









